Source Code String Cannot Contain Null Bytes
Source code strings containing null bytes can cause issues during parsing and compilation processes. It is crucial for developers to carefully sanitize input to ensure that the source code string cannot contain null bytes, mitigating potential vulnerabilities and ensuring the stability of their applications.
Author:Dr. Felix ChaosphereReviewer:Xander OddityMay 31, 20235.1K Shares225.6K Views

Null bytes, also known as null characters or '\0', are special characters that represent the end of a string in many programming languages. However, the presence of null bytes within a source code string can lead to unexpected behavior and pose challenges for developers.
Source code strings containing null bytes can cause issues during parsing and compilation processes. It is crucial for developers to carefully sanitize input to ensure that the source code string cannot contain null bytes, mitigating potential vulnerabilities and ensuring the stability of their applications.
Source Code String Cannot Contain Null Bytes
In programming, it is important to understand that source code strings cannot contain null bytes. Null bytes, also known as null characters or '\0', serve as string terminators in many programming languages.
When encountered within a string, null bytes indicate the end of the string and any characters following it are ignored. However, including null bytes within the source code itself can lead to unexpected behavior and pose challenges for developers.
The presence of null bytes in a source code string can cause compilation errors, syntax issues, and runtime problems. Compilers may interpret null bytes as the end of the string prematurely, resulting in syntax errors or failing to compile altogether. Moreover, at runtime, null bytes can lead to memory corruption, buffer overflows, and incorrect string manipulation operations.
The Problem With Null Bytes In Source Code Strings
While null bytes serve a crucial purpose within strings, they can become problematic when they unintentionally appear within the source code itself.
When a null byte is included within a string literal in the source code, it can lead to unexpected behavior during compilation, execution, or data processing. This issue is particularly prevalent in languages that rely heavily on null-terminated strings.
Impact On Compilation
Compiling source code containing null bytes can result in syntax errors or even complete failure to compile. The null byte is often interpreted as the end of a string, prematurely terminating the code that follows. As a result, the compiler may encounter unexpected characters or encounter invalid syntax.
Runtime Issues
When null bytes are present in a source code string, they can lead to runtime issues such as memory corruption or buffer overflows. For example, if a null byte is inadvertently included in a string that is read from a file, it may cause the program to incorrectly interpret the data or fail to read the entire string.
String Manipulation Challenges
String manipulation operations, such as searching, concatenation, or comparison, can also be affected by the presence of null bytes. Since null bytes signify the end of a string, any string manipulation function that relies on null-terminated strings may produce incorrect results or behave unexpectedly when encountering null bytes within the string.
Language-Specific Considerations
The impact of null bytes in source code strings varies across programming languages. Let's explore some language-specific considerations and behaviors related to this issue.
C And C++
In C and C++, null-terminated strings are fundamental. The standard library includes functions for string manipulation that rely on null-terminated strings. Consequently, null bytes within source code strings can lead to compilation errors or runtime issues.
Java
Java, unlike C and C++, does not use null-terminated strings. Instead, it relies on a length-based approach, where the length of the string is explicitly stored alongside the characters.
Consequently, null bytes within source code strings do not pose the same compilation or runtime issues in Java as they do in C or C++. However, Java still needs to handle null bytes correctly when interacting with other languages or when processing external data.
Python
Python treats strings as a sequence of Unicode characters and does not rely on null-terminated strings.
As a result, the presence of null bytes in source code strings does not cause the same compilation or runtime issues seen in languages like C or C++. However, certain string manipulation operations or external interactions may still require special handling to ensure proper behavior when null bytes are involved.
Mitigating The Issue
To mitigate the issue of null bytes in source code strings, developers can employ several strategies. Here are a few potential approaches:
Proper Input Validation
Ensure that any user input or external data is properly validated before using it within source code strings. This validation should include checking for the presence of null bytes and handling them appropriately, such as rejecting the input or converting null bytes to a different representation.
Language-Specific Techniques
Use language-specific techniques or libraries that provide string manipulation functions that handle null bytes correctly. These libraries often provide alternative functions that explicitly work with string lengths rather than relying on null-terminated strings.
Encoding And Decoding
If null bytes need to be included in source code strings for specific reasons, consider encoding the null byte using a different representation, such as hexadecimal or base64, and decoding it when necessary. This approach allows the inclusion of null bytes without encountering the issues associated with them.
Documentation And Best Practices
Educate developers about the implications of null bytes in source code strings and promote best practices for handling them. This includes guidelines for string manipulation, input validation, and interacting with external data sources.
Null Bytes In Database Management Systems
While null bytes are primarily associated with string manipulation in programming languages, they can also impact database management systems (DBMSs). In DBMSs, null bytes have specific implications that developers and database administrators should be aware of.
In the context of DBMSs, null bytes can affect data storage, querying, and indexing. Most DBMSs handle null values by storing a special marker to indicate the absence of a value in a particular field. However, if a null byte is present within a field's value, it can interfere with this mechanism and lead to unexpected behavior.
One common pitfall is the potential misinterpretation of null bytes as the end of a string, resulting in truncated data storage or inaccurate queries.
For example, if a null byte is inadvertently included in a text field, the DBMS may truncate the value at that point, leading to data loss. Similarly, queries that involve string comparison or concatenation may produce unexpected results due to the presence of null bytes.
To avoid these issues, developers and database administrators should implement proper data validation and ensure that null bytes are handled correctly within the DBMS. This may involve encoding or escaping strategies to represent null bytes differently or using specific functions or techniques provided by the DBMS to handle null values.

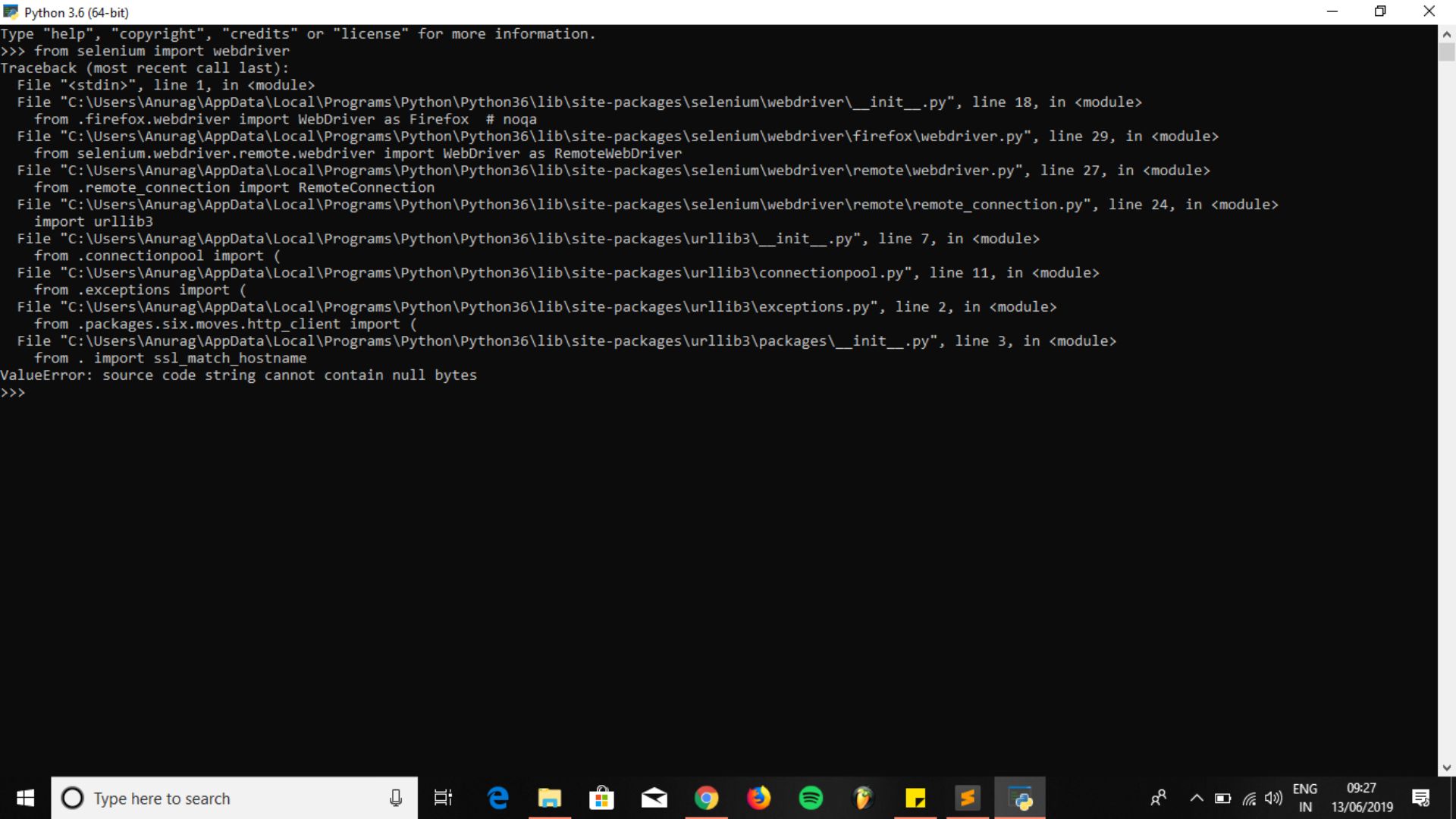
Django : Python Django ValueError: source code string cannot contain null bytes
Common Pitfalls When Dealing With Null Bytes
When dealing with null bytes in programming, developers must be mindful of various common pitfalls that can arise. These pitfalls, if not properly addressed, can lead to errors, vulnerabilities, and unexpected behavior in software systems.
One common pitfall is improper input validation. Failing to validate user input or external data can result in null bytes being present within strings, which can have unintended consequences. Developers should always validate input and ensure that it does not contain null bytes or handle them appropriately if they are allowed.
Another pitfall is relying on string manipulation functions or libraries that are not null-byte-aware. Many standard string manipulation functions assume null-terminated strings, and using them with strings containing null bytes can lead to incorrect results or crashes. It is important to use appropriate libraries or techniques that handle null bytes correctly or provide alternative functions that work with length-based strings.
Memory corruption is another potential pitfall. Null bytes within source code strings can lead to buffer overflows or other memory-related issues if not properly handled. Developers should be cautious when working with strings that may contain null bytes and ensure that memory buffers are allocated and managed correctly.
Additionally, neglecting proper documentation and training regarding null bytes can result in code that is vulnerable to bugs and security issues. It is essential to educate developers about the implications of null bytes and provide guidelines on best practices for handling them.
People Also Ask
Can Null Bytes Be Used As Regular Characters Within A String?
Null bytes cannot be used as regular characters within a string; they are typically used as string terminators.
Do All Programming Languages Treat Null Bytes In The Same Way?
No, different programming languages handle null bytes differently, depending on their string handling mechanisms.
How Can I Handle Null Bytes When Reading Input From A File?
When reading input from a file, it is important to validate and sanitize the data to ensure that null bytes are handled properly.
What Are The Potential Security Risks Associated With Null Bytes In Source Code Strings?
Null bytes can introduce security vulnerabilities, such as buffer overflows and data corruption, if not properly handled.
Is It Recommended To Explicitly Convert Null Bytes To A Different Representation?
Converting null bytes to a different representation can be useful in certain scenarios to ensure proper handling and avoid issues.
Conclusion
The presence of null bytes within source code strings can lead to unexpected behavior and challenges in software development. We explored how null bytes serve as string terminators in many programming languages, but their unintended presence in source code strings can cause compilation errors, runtime issues, and challenges with string manipulation.
It is important to note that a source code string cannot contain null bytes, as they are used as string terminators in programming languages. Therefore, developers should always ensure that their source code strings do not include null bytes to avoid any undesired consequences during compilation or runtime.

Dr. Felix Chaosphere
Author
Dr. Felix Chaosphere, a renowned and eccentric psychiatrist, is a master of unraveling the complexities of the human mind. With his wild and untamed hair, he embodies the essence of a brilliant but unconventional thinker. As a sexologist, he fearlessly delves into the depths of human desire and intimacy, unearthing hidden truths and challenging societal norms.
Beyond his professional expertise, Dr. Chaosphere is also a celebrated author, renowned for his provocative and thought-provoking literary works. His written words mirror the enigmatic nature of his persona, inviting readers to explore the labyrinthine corridors of the human psyche.
With his indomitable spirit and insatiable curiosity, Dr. Chaosphere continues to push boundaries, challenging society's preconceived notions and inspiring others to embrace their own inner tumult.

Xander Oddity
Reviewer
Xander Oddity, an eccentric and intrepid news reporter, is a master of unearthing the strange and bizarre. With an insatiable curiosity for the unconventional, Xander ventures into the depths of the unknown, fearlessly pursuing stories that defy conventional explanation. Armed with a vast reservoir of knowledge and experience in the realm of conspiracies, Xander is a seasoned investigator of the extraordinary.
Throughout his illustrious career, Xander has built a reputation for delving into the shadows of secrecy and unraveling the enigmatic. With an unyielding determination and an unwavering belief in the power of the bizarre, Xander strives to shed light on the unexplained and challenge the boundaries of conventional wisdom. In his pursuit of the truth, Xander continues to inspire others to question the world around them and embrace the unexpected.
Latest Articles
Popular Articles